
Degrees of freedom (df) are a fundamental concept in statistics that determine the number of independent values in a calculation. They play a crucial role in hypothesis testing, confidence intervals, and model fitting. Misunderstanding or miscalculating degrees of freedom can lead to inaccurate p-values, flawed conclusions, and unreliable results. Whether you're conducting a t-test, chi-square test, ANOVA, or linear regression, knowing how to correctly compute df is essential for valid statistical inference.
This guide breaks down the logic behind degrees of freedom and provides practical steps to calculate them across common statistical tests. By the end, you'll be equipped to confidently determine df in any scenario, ensuring your analyses stand up to scrutiny.
Understanding Degrees of Freedom: The Core Concept
Degrees of freedom represent the number of values in a calculation that are free to vary. When estimating a parameter—like the mean—you use data points to compute it, which imposes constraints on the remaining values. For example, if you know the mean of three numbers is 10, and two of the numbers are 8 and 12, the third must be 10. Only two values were free to vary; hence, there are 2 degrees of freedom.
In general terms:
“Degrees of freedom reflect the amount of information available to estimate variability. The more constraints in your model, the fewer degrees of freedom remain.” — Dr. Rebecca Lin, Biostatistician at Johns Hopkins University
This concept becomes critical when using probability distributions like the t-distribution, F-distribution, or chi-square distribution, all of which depend on df to determine critical values and tail probabilities.
Step-by-Step Guide to Calculating Degrees of Freedom
The formula for degrees of freedom varies depending on the statistical test being used. Below is a structured approach to identifying and calculating df across five major tests.
- Identify the type of statistical test: Determine whether you're performing a t-test, ANOVA, chi-square, or regression.
- Understand sample size(s): Note the total number of observations or groups involved.
- Account for estimated parameters: Each parameter estimated (e.g., mean, variance) reduces df by one.
- Apply the correct formula: Use the appropriate df rule based on design and test type.
- Verify assumptions: Ensure independence, random sampling, and correct grouping before finalizing df.
t-Tests: One-Sample and Two-Sample Scenarios
One-sample t-test: Compares a sample mean to a known population mean.
- Formula: df = n – 1
- Where n is the sample size.
Independent two-sample t-test: Compares means from two separate groups.
- Equal variances assumed: df = n₁ + n₂ – 2
- Unequal variances (Welch’s t-test): df is approximated using a more complex formula but generally less than n₁ + n₂ – 2.
Paired t-test: Used for dependent samples (e.g., pre- and post-treatment).
- df = n – 1, where n is the number of pairs.
Chi-Square Tests: Goodness-of-Fit and Independence
Chi-square goodness-of-fit test: Assesses whether observed frequencies match expected proportions.
- df = k – 1
- k = number of categories
Chi-square test of independence: Evaluates association between two categorical variables in a contingency table.
- df = (r – 1)(c – 1)
- r = number of rows, c = number of columns
For example, in a 3×4 contingency table, df = (3–1)(4–1) = 2×3 = 6.
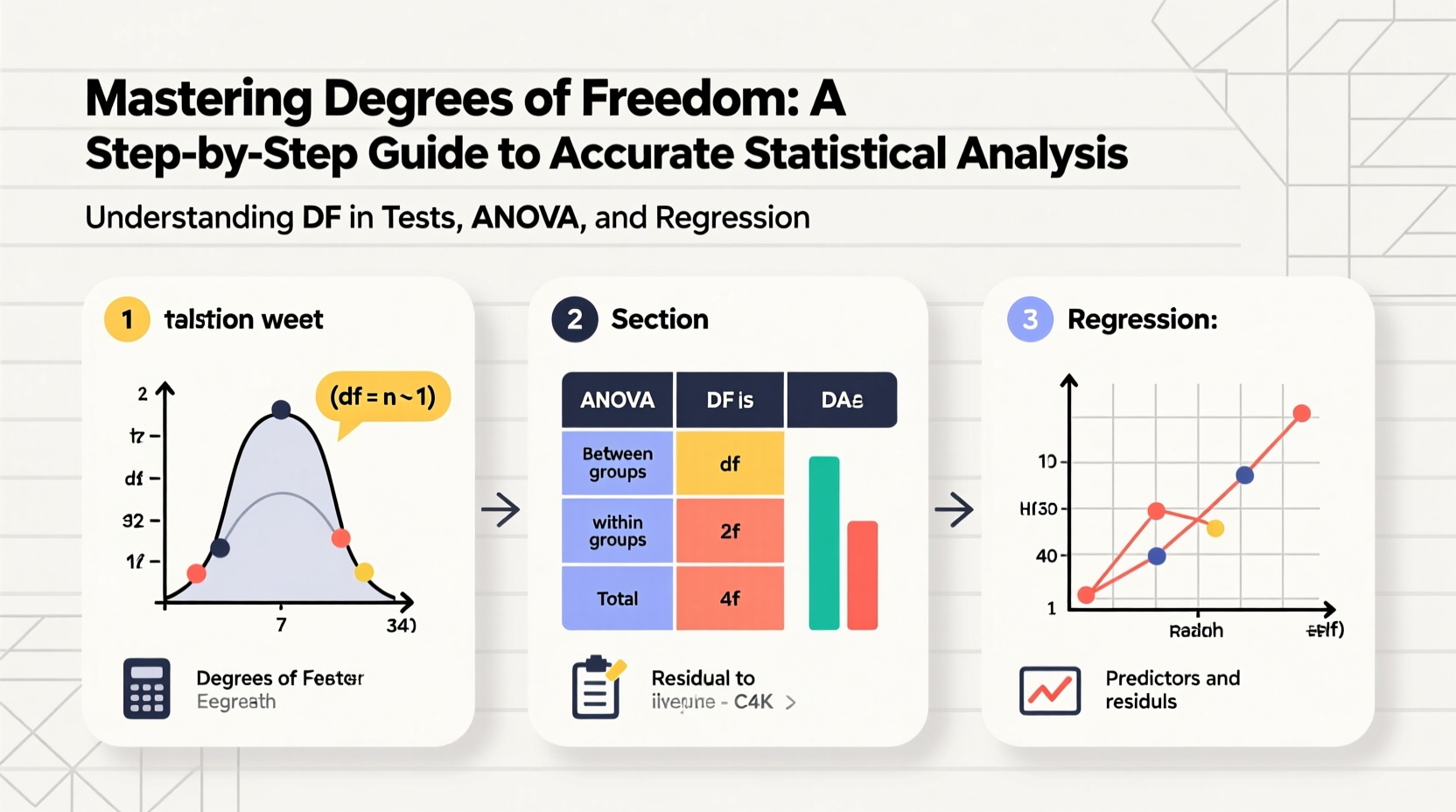
Analysis of Variance (ANOVA)
ANOVA compares means across three or more groups. It involves multiple degrees of freedom components.
| Source | Degrees of Freedom Formula | Description |
|---|---|---|
| Between Groups (Treatment) | k – 1 | k = number of groups |
| Within Groups (Error) | N – k | N = total sample size |
| Total | N – 1 | Sum of both components |
For instance, in a study with 5 groups and 60 total participants: df_between = 5–1 = 4, df_within = 60–5 = 55, df_total = 59.
Linear Regression
In simple linear regression (one predictor), degrees of freedom relate to the number of estimated coefficients.
- df_residual = n – 2
- n = sample size; subtract 2 for intercept and slope.
In multiple regression with k predictors:
- df_model = k
- df_residual = n – k – 1
- df_total = n – 1
These values are used to compute mean squares and F-statistics in the ANOVA table of regression output.
Common Mistakes and How to Avoid Them
Missteps in calculating degrees of freedom often stem from misunderstanding experimental design or misapplying formulas. Here are frequent errors and corrections:
| Mistake | Why It's Wrong | Correct Approach |
|---|---|---|
| Using n instead of n–1 in t-tests | Ignores estimation of the sample mean | Always reduce df by number of estimated parameters |
| Applying (r)(c) instead of (r–1)(c–1) in chi-square | Fails to account for marginal constraints | Subtract one from each dimension |
| Forgetting to adjust df in repeated measures ANOVA | Overestimates precision, inflates Type I error | Use within-subject df formulas or mixed-effects models |
Real-World Example: Clinical Trial Analysis
A pharmaceutical company conducts a clinical trial to compare blood pressure reduction across four drug formulations. They enroll 100 patients, randomly assigning 25 to each group. The researchers plan to use one-way ANOVA.
To determine degrees of freedom:
- Number of groups (k) = 4 → df_between = 4 – 1 = 3
- Total sample size (N) = 100 → df_within = 100 – 4 = 96
With df = (3, 96), they consult the F-distribution to find the critical value at α = 0.05. Using df correctly ensures accurate p-value interpretation. Had they mistakenly used df = 100 – 1 = 99 for error, the test would have been too liberal, risking false positives.
This case illustrates how proper df calculation directly impacts regulatory decisions and patient safety.
Checklist: Ensuring Accurate Degrees of Freedom
Before finalizing any statistical analysis, verify your df with this checklist:
- ✅ Identified the correct statistical test based on data type and research question
- ✅ Counted the number of groups, categories, or predictors accurately
- ✅ Subtracted one df for each estimated parameter (mean, slope, etc.)
- ✅ Applied the right formula for the test (e.g., (r–1)(c–1) for chi-square)
- ✅ Confirmed total df equals sum of component dfs in ANOVA/regression
- ✅ Cross-checked results with statistical software output
Frequently Asked Questions
Why do degrees of freedom matter in hypothesis testing?
Degrees of freedom define the shape of key statistical distributions (t, F, χ²). Using incorrect df leads to wrong critical values and p-values, increasing the risk of Type I or Type II errors. Accurate df ensures valid inference.
Can degrees of freedom be zero?
Yes, though rarely useful. If you have one observation and estimate one parameter (e.g., mean), df = 0. No variability remains to estimate error, making inference impossible. At least two observations are needed for a one-sample t-test.
What happens if I use too many predictors in regression relative to sample size?
You risk exhausting degrees of freedom. For example, with n = 10 and k = 8 predictors, df_residual = 10 – 8 – 1 = 1. This leads to unstable estimates, overfitting, and poor generalizability. A common rule is to have at least 10–20 observations per predictor.
Conclusion: Take Control of Your Statistical Accuracy
Degrees of freedom are not just a technical detail—they are foundational to sound statistical reasoning. From designing experiments to interpreting software output, understanding how to calculate df empowers you to produce trustworthy results. Whether you're a student, researcher, or analyst, mastering this concept enhances both your analytical rigor and credibility.








 浙公网安备
33010002000092号
浙公网安备
33010002000092号 浙B2-20120091-4
浙B2-20120091-4
Comments
No comments yet. Why don't you start the discussion?