
Building artificial intelligence software from the ground up is no longer reserved for elite research labs or tech giants. With accessible tools, open-source frameworks, and a growing body of knowledge, developers and engineers can now create powerful AI systems independently. However, success depends on more than just knowing how to run a machine learning model. It requires a structured approach, deep technical understanding, and strategic planning across multiple domains—from mathematics to system design.
This guide breaks down the core competencies and actionable strategies needed to develop AI software from scratch, offering a roadmap that balances theory with practical implementation.
1. Foundational Knowledge: The Core Pillars of AI Development
Before writing a single line of code, a solid grasp of the underlying principles is non-negotiable. AI development rests on three interlocking disciplines: mathematics, computer science, and domain-specific logic.
Mathematics forms the backbone of AI algorithms. Linear algebra enables operations on vectors and matrices used in neural networks. Calculus, particularly partial derivatives, underpins optimization techniques like gradient descent. Probability and statistics are essential for understanding uncertainty, making predictions, and evaluating models.
Computer science fundamentals include data structures (trees, graphs, hash tables), algorithm efficiency (Big O notation), and computational complexity. These ensure your AI system scales efficiently and performs reliably under real-world constraints.
Domain expertise—whether in healthcare, finance, or robotics—guides problem framing and ensures the AI solves meaningful challenges. A medical diagnosis model, for example, must align with clinical workflows and regulatory standards.
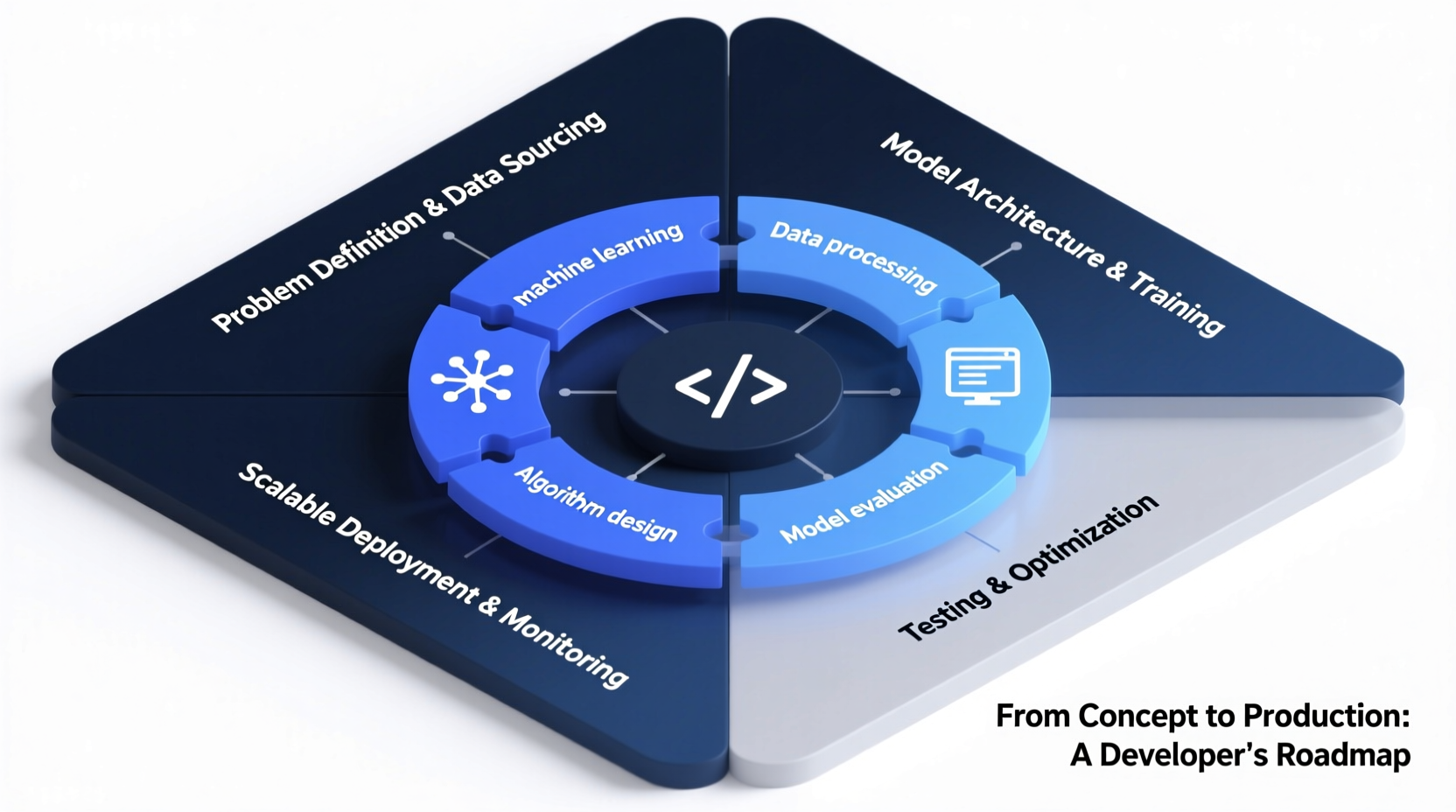
2. Step-by-Step Guide: Building an AI System from Scratch
Developing AI software isn’t a one-off task but a multi-phase process. Following a disciplined workflow minimizes wasted effort and increases reproducibility.
- Define the Problem Clearly: Identify the specific task—classification, prediction, generation—and determine measurable success criteria (e.g., accuracy, latency).
- Collect and Curate Data: Gather high-quality, representative datasets. Clean, label, and preprocess them to remove noise and bias.
- Select the Right Model Architecture: Choose between traditional ML models (like Random Forests) or deep learning (CNNs, Transformers) based on data type and complexity.
- Train and Validate Iteratively: Split data into training, validation, and test sets. Monitor metrics like loss and precision to detect overfitting.
- Optimize and Deploy: Refactor code for performance, containerize using Docker, and deploy via cloud services or edge devices.
- Monitor and Update: Track model drift, retrain with fresh data, and maintain version control for both code and datasets.
This lifecycle is iterative. Real-world feedback often leads back to earlier stages, such as collecting additional data or redesigning features.
3. Essential Technical Skills for AI Developers
Beyond theoretical knowledge, hands-on proficiency in key tools and languages separates capable developers from beginners.
| Skill Area | Key Tools & Languages | Why It Matters |
|---|---|---|
| Programming | Python, C++, JavaScript | Python dominates AI due to libraries like TensorFlow and PyTorch; C++ aids performance-critical components. |
| Data Handling | Pandas, NumPy, SQL, Apache Spark | Efficient data manipulation is critical for preprocessing large-scale datasets. |
| Machine Learning Frameworks | Scikit-learn, Keras, Hugging Face | Accelerate development with pre-built modules and pretrained models. |
| DevOps & Deployment | Docker, Kubernetes, FastAPI, AWS/GCP | Ensure models run reliably in production environments. |
| Version Control | Git, DVC (Data Version Control) | Track changes in code and datasets for collaboration and reproducibility. |
Mastery of these tools enables seamless transition from prototype to production-grade systems.
4. Mini Case Study: Building a Custom Fraud Detection Engine
A fintech startup aimed to reduce transaction fraud using AI. Their team began by analyzing historical transaction logs, identifying patterns such as unusual geolocation jumps and rapid successive purchases.
They collected six months of anonymized data, balanced the dataset to address class imbalance, and engineered features like time since last login and average transaction amount. Using XGBoost for interpretability and speed, they trained a classifier achieving 94% precision on holdout data.
The model was deployed via a REST API using FastAPI and integrated into their payment gateway. Over three months, fraudulent transactions dropped by 38%. Continuous monitoring revealed concept drift during holiday seasons, prompting scheduled retraining.
This case illustrates how combining domain insight with disciplined engineering yields tangible results.
“AI isn’t magic—it’s meticulous data work wrapped in smart algorithms.” — Dr. Lena Patel, Senior AI Engineer at Stripe
5. Checklist: Preparing Your First AI Project
Before launching your own AI initiative, verify the following:
- ✅ Defined a clear, measurable objective
- ✅ Secured access to sufficient, high-quality data
- ✅ Selected appropriate evaluation metrics (e.g., F1-score, AUC-ROC)
- ✅ Set up a version-controlled development environment (Git + DVC)
- ✅ Chosen a scalable infrastructure (local GPU, cloud instance, or TPU)
- ✅ Planned for ethical considerations (bias audits, privacy compliance)
- ✅ Designed a deployment strategy (API, mobile integration, batch processing)
Skipping any of these steps risks project failure or unreliable outputs.
6. Common Pitfalls and How to Avoid Them
Many AI projects fail not due to technical limitations, but avoidable mistakes in planning and execution.
Overfitting complex models to small datasets is a frequent error. Combat this with cross-validation, regularization, and early stopping.
Neglecting data quality undermines even the most advanced architectures. Invest time in exploratory data analysis (EDA) and outlier detection.
Ignoring scalability leads to models that work in Jupyter notebooks but fail under load. Design with production in mind from day one.
Underestimating ethical risks, such as biased decision-making, can damage user trust and lead to legal issues. Conduct fairness audits and document model limitations.
7. Frequently Asked Questions
Can I build AI software without a PhD?
Absolutely. While advanced research may require deep academic training, many impactful AI applications—such as chatbots, recommendation engines, and image classifiers—can be built with online courses, open-source tools, and disciplined practice.
How much data do I need to train an AI model?
It depends on the problem and model complexity. Simple tasks may require only thousands of samples; deep learning models often need hundreds of thousands. Data augmentation and transfer learning can help when data is limited.
Is it better to use pre-trained models or build from scratch?
In most cases, starting with a pre-trained model (e.g., BERT for NLP or ResNet for vision) saves time and improves performance. Fine-tune it on your specific dataset rather than training from random initialization.
Conclusion: Start Small, Think Big
Developing AI software from scratch is challenging but entirely achievable with the right mindset and methodology. Focus on mastering fundamentals, embrace iteration, and prioritize real-world impact over technical novelty. Every expert AI developer started with a single line of code and a willingness to learn.








 浙公网安备
33010002000092号
浙公网安备
33010002000092号 浙B2-20120091-4
浙B2-20120091-4
Comments
No comments yet. Why don't you start the discussion?